 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIS: Adaptive Importance Sampling for Quantized RL
May 13, 2026Reinforcement learning (RL) for large language models (LLMs) is dominated by the cost of rollout generation, which has motivated the use of low-precision rollouts (e.g., FP8) paired with a BF16 trainer to improve throughput and reduce memory pressure. This introduces a rollout-training mismatch that biases the policy gradient and can cause training to collapse outright on reasoning benchmarks. We show that the mismatch is non-stationary and acts as a double-edged sword: early in training it provides a stochastic exploration bonus, exposing the gradient to trajectories the trainer would otherwise under-sample, but the same perturbation transitions into a destabilizing source of bias as the policy concentrates. To solve this, we propose Adaptive Importance Sampling (AIS), a correction framework that adjusts the strength of its intervention on a per-batch basis. AIS combines three real-time diagnostics, namely weight reliability, divergence severity, and variance amplification, into a single mixing coefficient that interpolates between the uncorrected and fully importance-weighted gradients, suppressing the destabilizing component of the mismatch while preserving its exploratory benefit. We integrate AIS into GRPO and evaluate it on the diffusion-based LLaDA-8B-Instruct and the autoregressive Qwen3-8B and Qwen3.5-9B across mathematical reasoning and planning benchmarks. AIS matches the BF16 baseline on most tasks while retaining the 1.5 to 2.76x rollout speedup of FP8.
Multi-Scale Dequant: Eliminating Dequantization Bottleneck via Activation Decomposition for Efficient LLM Inference
May 13, 2026Quantization is essential for efficient large language model (LLM) inference, yet the dequantization step-converting low-bit weights back to high-precision for matrix multiplication has become a critical bottleneck on modern AI accelerators. On architectures with decoupled compute units (e.g., Ascend NPUs), dequantization operations can consume more cycles than the matrix multiplication itself, leaving the high-throughput tensor cores underutilized. This paper presents Multi-Scale Dequant (MSD), a quantization framework that removes weight/KV dequantization from the GEMM critical path. Instead of lifting low-bit weights to BF16 precision, MSD decomposes high-precision BF16 activations into multiple low-precision components, each of which can be multiplied directly with quantized weights via native hardware-accelerated GEMM. This approach shifts the computational paradigm from precision conversion to multi-scale approximation, avoiding INT8-to-BF16 weight conversion before GEMM. We instantiate MSD for two weight formats and derive tight error bounds for each. For INT8 weights (W4A16), two-pass INT8 decomposition achieves near 16 effective bits. For MXFP4 weights (W4A16), two-pass MXFP4 decomposition yields near 6.6 effective bits with error bound 1/64 per block surpassing single-pass MXFP8(5.24 bits) while maintaining the same effective GEMM compute time. We further derive closed-form latency and HBM traffic models showing that MSD avoids the Vector-Cube pipeline stall caused by dequantization and reduces KV cache HBM traffic by up to 2.5 times in attention. Numerical simulations on matrix multiplication and Flash Attention kernels confirm that MSD does not degrade accuracy compared to dequantization baselines, and in many settings achieves lower L2 error.
Theoretically Optimal Attention/FFN Ratios in Disaggregated LLM Serving
Jan 29, 2026Attention-FFN disaggregation (AFD) is an emerging architecture for LLM decoding that separates state-heavy, KV-cache-dominated Attention computation from stateless, compute-intensive FFN computation, connected by per-step communication. While AFD enables independent scaling of memory and compute resources, its performance is highly sensitive to the Attention/FFN provisioning ratio: mis-sizing induces step-level blocking and costly device idle time. We develop a tractable analytical framework for sizing AFD bundles in an $r$A-$1$F topology, where the key difficulty is that Attention-side work is nonstationary-token context grows and requests are continuously replenished with random lengths-while FFN work is stable given the aggregated batch. Using a probabilistic workload model, we derive closed-form rules for the optimal A/F ratio that maximize average throughput per instance across the system. A trace-calibrated AFD simulator validates the theory: across workloads, the theoretical optimal A/F ratio matches the simulation-optimal within 10%, and consistently reduces idle time.
LoPT: Lossless Parallel Tokenization Acceleration for Long Context Inference of Large Language Model
Nov 07, 2025Long context inference scenarios have become increasingly important for large language models, yet they introduce significant computational latency. While prior research has optimized long-sequence inference through operators, model architectures, and system frameworks, tokenization remains an overlooked bottleneck. Existing parallel tokenization methods accelerate processing through text segmentation and multi-process tokenization, but they suffer from inconsistent results due to boundary artifacts that occur after merging. To address this, we propose LoPT, a novel Lossless Parallel Tokenization framework that ensures output identical to standard sequential tokenization. Our approach employs character-position-based matching and dynamic chunk length adjustment to align and merge tokenized segments accurately. Extensive experiments across diverse long-text datasets demonstrate that LoPT achieves significant speedup while guaranteeing lossless tokenization. We also provide theoretical proof of consistency and comprehensive analytical studies to validate the robustness of our method.
Fine-Tuning Pre-trained Large Time Series Models for Prediction of Wind Turbine SCADA Data
Nov 30, 2024



The remarkable achievements of large models in the fields of natural language processing (NLP) and computer vision (CV) have sparked interest in their application to time series forecasting within industrial contexts. This paper explores the application of a pre-trained large time series model, Timer, which was initially trained on a wide range of time series data from multiple domains, in the prediction of Supervisory Control and Data Acquisition (SCADA) data collected from wind turbines. The model was fine-tuned on SCADA datasets sourced from two wind farms, which exhibited differing characteristics, and its accuracy was subsequently evaluated. Additionally, the impact of data volume was studied to evaluate the few-shot ability of the Timer. Finally, an application study on one-turbine fine-tuning for whole-plant prediction was implemented where both few-shot and cross-turbine generalization capacity is required. The results reveal that the pre-trained large model does not consistently outperform other baseline models in terms of prediction accuracy whenever the data is abundant or not, but demonstrates superior performance in the application study. This result underscores the distinctive advantages of the pre-trained large time series model in facilitating swift deployment.
Domain-specific ReAct for physics-integrated iterative modeling: A case study of LLM agents for gas path analysis of gas turbines
Jun 01, 2024



This study explores the application of large language models (LLMs) with callable tools in energy and power engineering domain, focusing on gas path analysis of gas turbines. We developed a dual-agent tool-calling process to integrate expert knowledge, predefined tools, and LLM reasoning. We evaluated various LLMs, including LLama3, Qwen1.5 and GPT. Smaller models struggled with tool usage and parameter extraction, while larger models demonstrated favorable capabilities. All models faced challenges with complex, multi-component problems. Based on the test results, we infer that LLMs with nearly 100 billion parameters could meet professional scenario requirements with fine-tuning and advanced prompt design. Continued development are likely to enhance their accuracy and effectiveness, paving the way for more robust AI-driven solutions.
Solving Inverse Wave Scattering with Deep Learning
Nov 27, 2019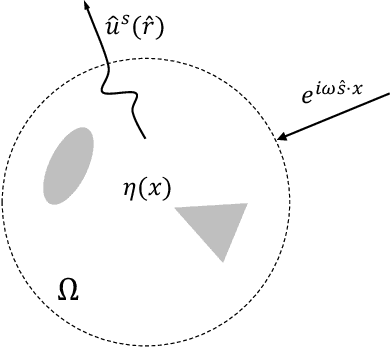
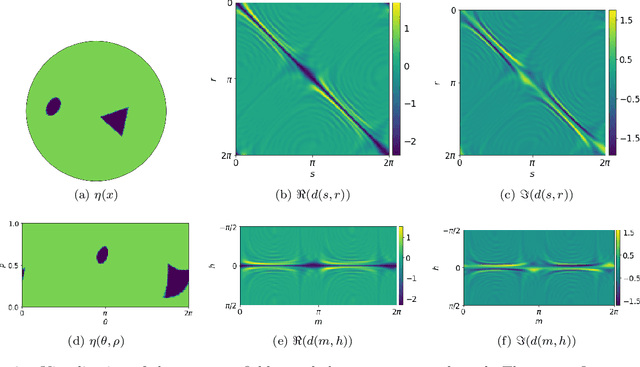
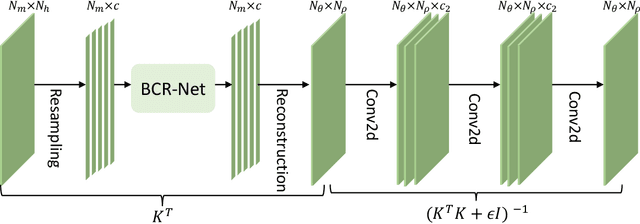
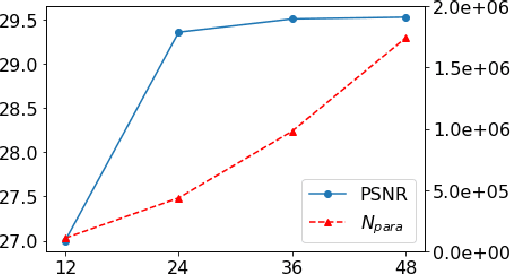
This paper proposes a neural network approach for solving two classical problems in the two-dimensional inverse wave scattering: far field pattern problem and seismic imaging. The mathematical problem of inverse wave scattering is to recover the scatterer field of a medium based on the boundary measurement of the scattered wave from the medium, which is high-dimensional and nonlinear. For the far field pattern problem under the circular experimental setup, a perturbative analysis shows that the forward map can be approximated by a vectorized convolution operator in the angular direction. Motivated by this and filtered back-projection, we propose an effective neural network architecture for the inverse map using the recently introduced BCR-Net along with the standard convolution layers. Analogously for the seismic imaging problem, we propose a similar neural network architecture under the rectangular domain setup with a depth-dependent background velocity. Numerical results demonstrate the efficiency of the proposed neural networks.
Solving Traveltime Tomography with Deep Learning
Nov 25, 2019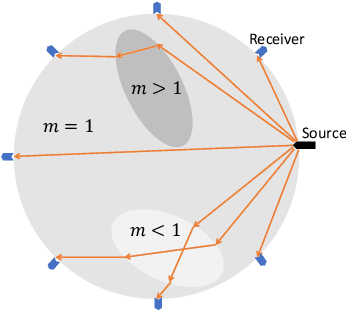
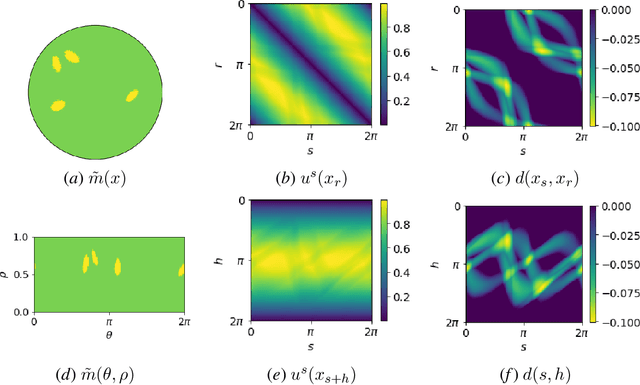
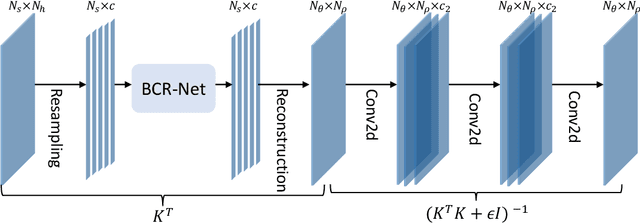
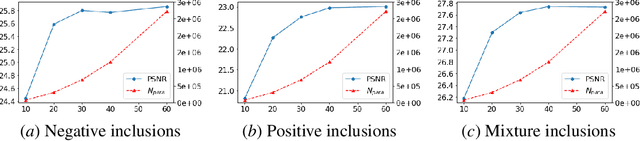
This paper introduces a neural network approach for solving two-dimensional traveltime tomography (TT) problems based on the eikonal equation. The mathematical problem of TT is to recover the slowness field of a medium based on the boundary measurement of the traveltimes of waves going through the medium. This inverse map is high-dimensional and nonlinear. For the circular tomography geometry, a perturbative analysis shows that the forward map can be approximated by a vectorized convolution operator in the angular direction. Motivated by this and filtered back-projection, we propose an effective neural network architecture for the inverse map using the recently proposed BCR-Net, with weights learned from training datasets. Numerical results demonstrate the efficiency of the proposed neural networks.
Solving Optical Tomography with Deep Learning
Oct 10, 2019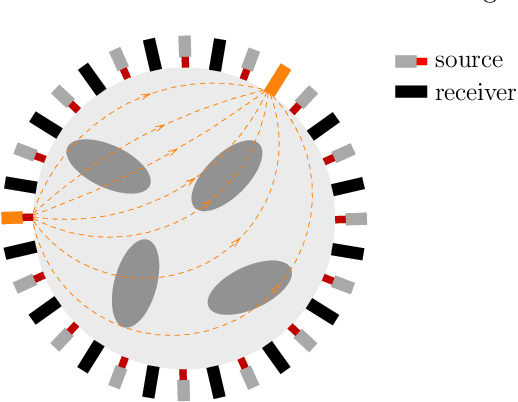
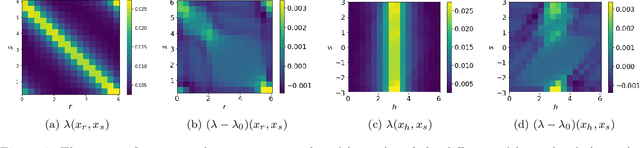
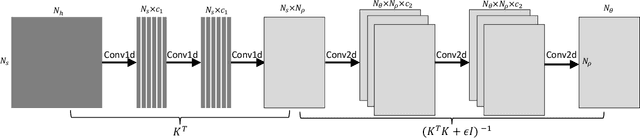
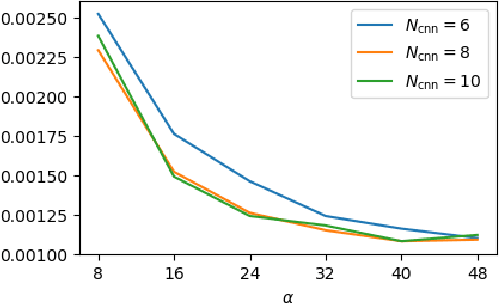
This paper presents a neural network approach for solving two-dimensional optical tomography (OT) problems based on the radiative transfer equation. The mathematical problem of OT is to recover the optical properties of an object based on the albedo operator that is accessible from boundary measurements. Both the forward map from the optical properties to the albedo operator and the inverse map are high-dimensional and nonlinear. For the circular tomography geometry, a perturbative analysis shows that the forward map can be approximated by a vectorized convolution operator in the angular direction. Motivated by this, we propose effective neural network architectures for the forward and inverse maps based on convolution layers, with weights learned from training datasets. Numerical results demonstrate the efficiency of the proposed neural networks.
Meta-learning Pseudo-differential Operators with Deep Neural Networks
Jun 16, 2019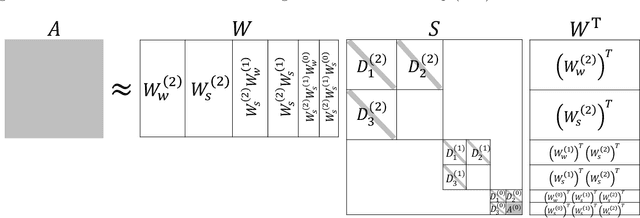
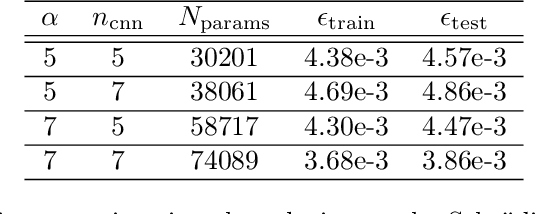
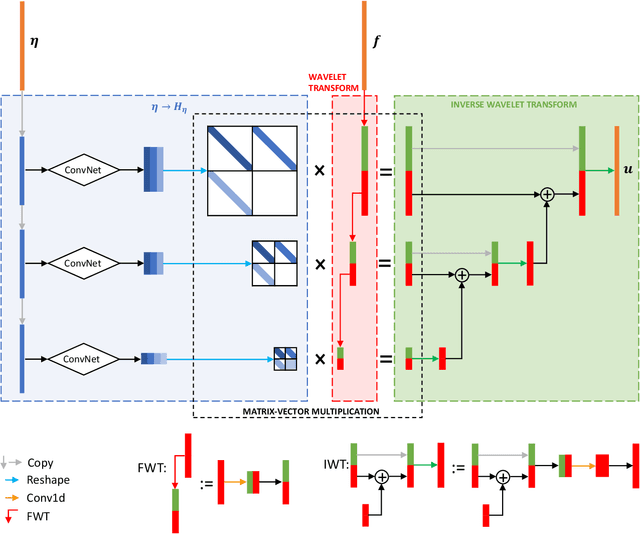

This paper introduces a meta-learning approach for parameterized pseudo-differential operators with deep neural networks. With the help of the nonstandard wavelet form, the pseudo-differential operators can be approximated in a compressed form with a collection of vectors. The nonlinear map from the parameter to this collection of vectors and the wavelet transform are learned together from a small number of matrix-vector multiplications of the pseudo-differential operator. Numerical results for Green's functions of elliptic partial differential equations and the radiative transfer equations demonstrate the efficiency and accuracy of the proposed approach.